1. HT… something: HTML and HTTP
2. That which we call a rose is a web resource: URIS, URLs and URNs
3. Overview of the protocol: connection, request and response
4. Asking nicely for content: what client requests look like
5.1 Common response status codes
6. Further reading and resources
Deeper into the HTTP rabbithole
Note: if you just want a quick overview of how HTTP works, head to Section 3.
When Tim Berners-Lee invented the World Wide Web in 1989, he had more in mind than just the free exchange of files around a network of computers: his design conveyed the idea of hypertext or linked documents: structured resources connected to each other through cross references that could be not only explored and retrieved in real time, but also searched, updated and even annotated on (HTTP RFC, Section 1.1) through an interface. This article being delivered to you on a website through a browser is an example of such a document. It has links to related terms that you can click on and navigate to. How does this happen?
1. HT… something: HTML and HTTP
The two sister technologies that make exchanges on the Web possible are the Hypertext Markup Language (HTML) and the Hypertext Transfer Protocol (HTTP). Both start with HT because they are dealing with the same stuff, hypertext, that is.
HTML defines how a document should be formatted in order to play in this sharing environment we call the Web and HTTP defines how this document and its resources (see Section 2) get from one computer to another. Both are sets of instructions, or protocols. HTML defines structure, HTTP transport.
Although this article does not attempt to go into too much detail into how HTML works, it is worth talking a bit about markup before we delve into HTTP.
The Concise Oxford English Dictionary defines markup, in the computational arena, as “a set of tags assigned to elements of a text to indicate their relation to the rest of the text or dictate how they should be displayed”. The key term to keep in mind here is tags.
When your human eyes rest on a document that has a certain constant visual hierarchy, you can infer which parts of it are titles, subtitles, paragraphs, lists and so on. Computers and the browsers that operate in them are not as smart. You need to tell them which parts are which with tags (Fig. 1).

A HTML tag looks like this:
<title> A gentle introduction to HTTP </title>
The actual tag is defined inside the characters < > </>. The text in between is the actual content in the case of text, and other multimedia items have other rules (but don’t worry about this for now).
Modern HTML’s standards are to a great extent designed so that tags are semantic, namely, that they accurately describe the element contained within them. This sounds obvious, but a tag <cat> </cat> might not be ideal to contain information about, say, pugs. Jeffrey Zeldman and Ethan Marcotte make a strong argument on the importance of semantic structuring of documents in their Designing with Web Standards book, which is a fantastic primer in HTML and other web technologies well worth looking into if you want to dig deeper into these subjects (you’ll want to look at the 3rd edition, the most current version of this text, from 2010).
So, with the idea of tagged resources in mind, let’s move on to HTTP. Why would you want to learn about it, anyway? If you are at ITP, you might want at some point create things and connect them to the Internet. If you are ready to move from your Github page or your just another WordPress site, you will find useful to learn about HTTP to get your hyperlinked creations get out there.
This document aims to be a friendly overview of how the HTTP protocol works and point to some further readings in case you want to dig deeper into the subject.
2. That which we call a rose is a web resource: URIS, URLs and URNs
Web resources take many forms. They might be text or data, images, video or other multimedia as well as information that specifies aspects of presentation and behavior–like CSS and Javascript files– of a web document.
A resource is a workable/shareable item on the internet when it has a Unified Resource Identifier, or URI. The URI could indicate a name of a resource, where it’s located, or both. Here’s an example of a URI:
www.pbs.org/video/nova-first-man-moon/
You might be more familiar with the term Unified Resource Locator, or URL. URLs are URIs that in addition of pointing to the resource, they also indicate the mechanism to access it (like HTTP, HTTPs or FTP). This is what you see on your address/search bar. Following with our previous example, a URL will look like this:
http://www.pbs.org/video/nova-first-man-moon/
Another term that you might run into is Unified Resource Name or URN, which would look like the first example:
www.pbs.org/video/nova-first-man-moon/
This can be a very confusing rabbit hole to dive into, the important thing to remember is that all three terms refer roughly to the same thing, but when you have an address to a resource that indicates the method to get it (eg.: HTTP://), you are looking at a URL. All URLs are URIs, but not all URIs are URLs (they can just be URNs). The bigger group is URIs (Figure 2). If you want to keep ruminating on this all roses are red (supposing they were), but not all red things are roses thread check out Daniel Miessler’s article on the subject.

3. Overview of the protocol: connection, request and response
The two main players that make use of the HTTP protocol are clients and servers. This is how they tango: clients request to be connected to a certain server from where they want to pull up resources and the server accepts the connection. If this goes well then the client will request content and the server with respond with the requested resource. Both clients and servers are software programs. In between these two there may be additional middlemen often referred to as proxies that do a number of additional things (like logging in, filtering, caching, etc.), but they are beyond the scope of this article, but a good resource to look at if you want to learn more is the Mozilla Developer Network documentation on HTTP).
For this overview we are assuming that all sides are completely functional and playing by the rules (we will briefly mention how the server responds in case something goes wrong in Section 5). So the mechanics of the HTTP protocol can be divided into three main chunks: connection, request and response (Figure 3).
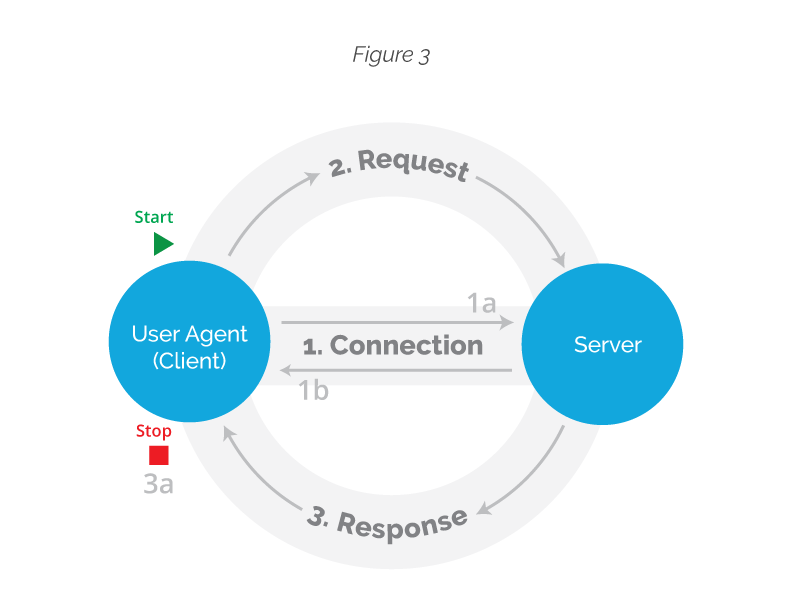
The World Wide Web Consortium, or W3C, provided a very straightforward description of how this breaks down (note, this is from the 1991 specification, but the mechanics remain roughly the same):
- The client starts off by asking to make a TCP/IP connection to the server using the domain name (eg. http://bobcat.library.nyu.edu/) or its IP number equivalent (128.122.149.83, in the case of our example site) and the specific port number given in the address (Borrowing a metaphor from Charles Severance’s introductory course to Internet technologies, if a domain name or IP were to be taken as a phone number for an organization, a port would be the extension to locate a specific person inside this organization, here are some common port numbers).
- The server accepts the connection.
- The client sends a request to the server. A request is a document, or a set of ASCII characters where it defines what it wants to do with the server (it might want to get a specific resource, post information to the server, or even delete stuff from it. More on this on Section 4).
- The server answers to the client’s request with a document in HTML format (this is the actual resource a browser requests) and a message to notify the client if it has been successful or not in attending its demands (see Section 5 for some examples of these responses).
- The server ends the connection, or the session, when the full resource has been transferred.
This article will not cover TCP/IP connection and will take it as a given, this is, we will assume this part is running smoothly and the parts don’t close the connection until the whole transaction has been made and we will proceed to an overview of requests and responses.
4. Asking nicely for content: what client requests look like
When you request through your browser to access a certain website, you don’t receive all the content at once (although it sure feels like it!) Rather, all the components that make up that site are sent by the server as a series of requests for different resources that, like puzzle pieces, the browser then interprets, assembles and displays on your screen.
Clients manifest in the form of user agents (this is probably the name you’ll run into when looking at other HTTP documentation) and the most common one is the web browser.
Other user agents that you might have heard of are spiders (or website bots, the ones that Google uses to link pages to its search engine) phone apps, programs working on your computer that are connected to the Internet without the aid of a browser, Internet of Things (IoT) devices (like Amazon’s Echo or Google Home), amongst other tools that may or may not have a human user behind them.
Different user agents will have different content needs and HTTP is flexible enough to cater to many client needs. When the Echo speaker connects to the Internet, for example, it has no use for images, so the server could potentially send to it a different document than the one that would be delivered to your browser. Let’s stick with the browser case, as we have throughout this article, as this is probably the client you are most familiar with.
It is also important to remember from Section 3, that you, as the user utilizing a client/user agent (your browser), are always the one that starts the conversation, that is, you request information, and you do so using the rules set by HTTP.
So, you might be wondering, how does your browser asks for information in a polite, protocol-complying manner?
Well, it makes a specific request defining what it wants to do with the server. Requests have the following elements:
- Method: we specify what we are asking for with it. The most common ones are GET and POST. When you want to simply browse through a web page, for example, you are using a GET method, when you fill out a form and send it to a browser you send information to a server, which then stores it somewhere. Here’s the MDN reference if you want to look at other methods.
- Version: our request must specify the version of HTTP we are using (probably 1.1, which is the one we’ve been discussing throughout this article, although be aware that there is a HTTP2 version out there as well).
- URI: we also include the resource identifier (see Section 2).
- Header: these are fields that contain information like details about the client (that’s our browser!) and other metadata, like the type of content being sent.
- Body: the actual resource, if we are sending something (eg. when using the POST method).
As mentioned in Section 3, what follows is that your browser will wait for a response and then either keep the connection alive for further requests or close the connection. If you want to see how HTTP headers look like on a page you are browsing you can install and use tools like the HTTP Headers Chrome extension.
5. How the server responds
The server’s response is very similarly to our request, that is, it will also indicate the version of HTTP it is using and will also include headers with information about the request. In addition to this, it will also attach a response number indicating the status of the request (if it is successful in fetching the resource, it will return a 200). You are probably most familiar with the response you get when it can’t find the resource: the infamous 404: not found, which will be displayed on your screen. On a successful normal browser scenario you, the end user, will not see the 200. Your browser does, however, and that is all that matters. Successful requests will also include the actual resource you were requesting (if you were using a GET method).
5.1 Common response status codes
Response status codes are good to know about specially when your request is not successful and you want to find about what went wrong. The following list is by no means exhaustive (but here’s a link to an exhaustive list), but it gives you an idea of where common responses are in the overall scheme:
100s: informational
200s: all is well, your request has been received, understood, accepted.
- Example: the good old 200, which indicates that the content you requested has been delivered
300: redirection
400s: uh-oh! there is something wrong with the request (it could be your fault, but not necessarily)
- Example: 404, the resource you are looking for can’t be found. This is the classic thing that happens when you type a URL wrong, but this also appears when people on the other side changed the name of the resource and didn’t update their links or refer to the change like considerate people do.
500s: uh-oh! there is something wrong on the server side
- Example: 503, service unavailable: might appear when the server is too busy handling requests or is under maintenance, therefore it can’t take requests.
6. Further readings and resources
I hope you have found this guide useful. I just want to end by saying that as a resource exchange protocol, HTTP defines how things should be, but in real life developers might not adhere to it and make arbitrary decisions when building their systems. That can be frustrating. If you are planning to work on server side stuff, please try be a nice standards complying fellow and try to play by the rules. The Internet will thank you.
This guide is by no means exhaustive. Below are some sites that I delved into to write this article that you might want to explore on your own:
6.1 Deeper into the HTTP rabbit hole
- The HTTP 1.1 Request For Comment (RFC) Document is the most comprehensive documentation on this protocol.
- All the Mozilla Development Network Documentation has great guides and is an excellent reference.
6.2 HTTP vs HTTPS
When using the HTTP protocol to transfer resources the data going through the cables of the Internet is not secure. The information your browser and a server are exchanging is an open book and a person that has the tools and knowledge to intercept Internet packets (these are the smallest unit of information that travels through the internet) can peek. If you are handling information you don’t want other people to look at HTTPS is the more secure protocol option. Here’s a quick comparison between both.