by Tracey Shi
Summary
A Cryptographic Hash Function(CHF) is an algorithm equation that converts any given length of data into a unique, fixed-length numerical bit that maps the given input value. The computational process is one-way, hence once the hash value is generated, it can not be decoded, converted or retrieved back to its original data. In programming practice, hash functions are commonly used to verify the file which it was assigned to, ensuring the safety, authenticity and integrity of the data.
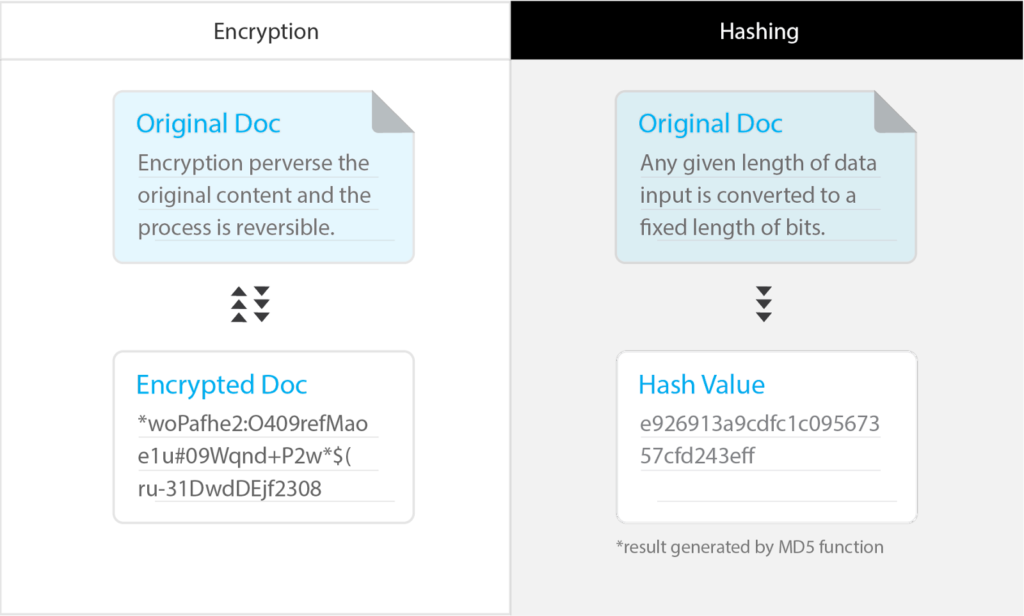
When speaking of hashing, the common misconception is equating the functionality of a hash to encryption. Though sometimes the two are used in conjunction with each other for practicing safer security protocols, they operate on different methodologies and functionalities. The main difference is that an encrypted file can be decrypted and translated back to the original document, whereas hashing is irreversible. The premise of encryption is exactly what it sounds like – to encode data into a different piece of information. Hashing, on the other hand, can be used as a digital signature to verify the data. For example, the receiver can hash the received file by using the same algorithms embedded in the file, then comparing the generated hash to the received hash. Through this process, the receiver can check if the data has been kept intact if the hash value does not match up.
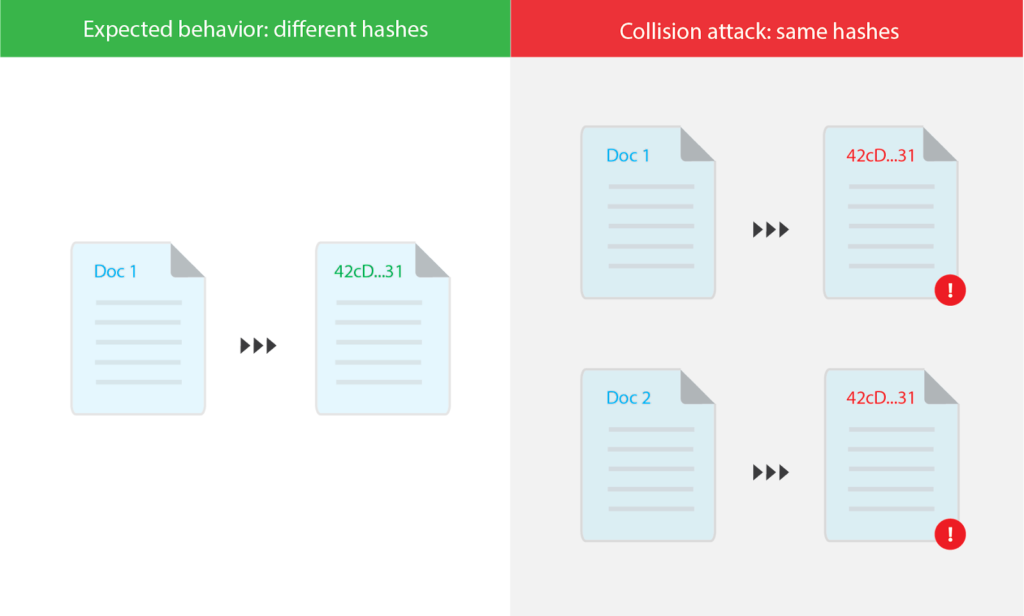
Unlike encryption, in which the length of coded digits completely depends on its file size, hashing has a fixed length of bits for any given document, independent of the file sizes, formats or types. In rare occasions when the original documents are relatively lightweight and using broken, outdated hash functions, different data can have identical hash digests, hence creating the problem of hashing collision.
History
So where did the idea of hashing come from? It actually has been a standard practice within Jewish communities for centuries to make Torah scroll copies (source). Every scroll is painstakingly handwritten by Jewish Rabbis, marking and tracking the columns, numbers, and letters on the page to see if they match with the original document. The total sums of the letters need to be consistent for every single copy, and bears zero tolerance of mistakes.

Common Application
In general, hash functions are widely used in cryptography and for cryptocurrency with varying levels of structural complexity and difficulty. Common applications include browser security, password security, managing code repositories, authenticating data transfer, message security or “even just detecting duplicate files in storage”.
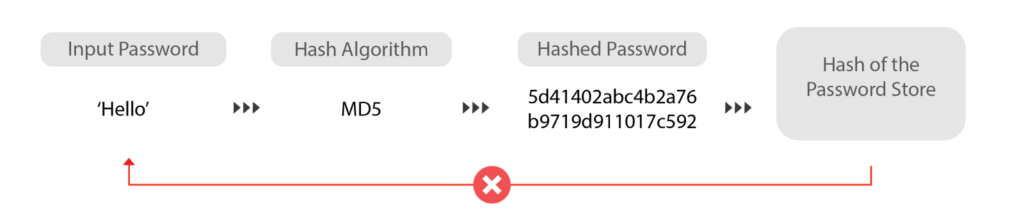
- Password Verification and Storage. Hashing is used for providing matching passwords and user credentials for authentication. When a user writes a clear text password alongside their username, hashing is used to give the pair a hash value stored in the database. The next time when a user logs into the account, their input password is again hashed and the resulting hashed password is used to compare if it matches with the user’s credentials. During this process, the user does not have to worry about their clear text password getting stored in the back end, because it has all been hashed into fixed digests of bits that resemble nothing like the original password (Source).
- Digital signature generation. It can be used for authenticating digital documents, data or messages, from which one can solve the digest through a given signature verifying algorithm and private key to match the output value to its input data.
- Verify data integrity. Making sure the data is kept intact and secure during electronic transit.
Prerequisites for effective hash function
In practice, an effective hash function should meet certain protocol requirements in order to provide users with safe transfer and verified data pieces.
- Speed. The speed of the hash needs to be very balanced. It needs to be fast enough to hash big files within a reasonable time frame but not too fast in which the progress can be easily copied and tempered with by others.
- An unique hash value for every input. Any change of bits occurring within the original data directly reflects upon the change of its encoded hash function, also known as the Avalanche effect as to prevent hash collision.
- Uniformly distributed. The function should have ways to provide alternative index value to previously stored output in a hash table so as to avoid clustering the hash table.
Common type of hash function
- Secure HasMessage Direct (MD4, MD5) – Commonly used for protecting integrity of the file
- h Function (SHA-1) – First developed by the US National Security Agency. Also considered insecure and “unreliable for generating unique checksums” in 2005.
- Secure Hash Function (SHA-256) – improved since SHA-1 family with increased digest length (bits) in hash function, commonly used in bitcoin for integrity and block-chaining.
Hashing Collision
Although unlikely, sometimes different pieces of data can have the exact same message digest, the occurrence of which is called Hashing Collision. To generate a hash function, one needs to run the file through a computationally taxing algorithm, therefore in practice, any super computer has the power to run an algorithm millions of times until an identical hash function is generated. In real life, just think about the probability of someone having an exact birth time and date with you, within milliseconds. Although the chance is low, the probability of having a distant twin does exist,unbeknownst to you. So when the odds are happening in hashing, it creates a security loophole for malicious internet activities that are not only causing damages to the original file, but also inviting fraudulent practices, such as faking documents by tweaking the small bits until a recurring hash value comes out. Ensuring security of the file is a top priority of hashing, hence when it’s vulnerable to attacks, it loses credibility, and security practitioners have to move forward with developing safer cryptographic hashes.
Example of a broken hash function
MD5 is a long used hash function that produces 128 bits of hash value. It was now thoroughly broken and replaced by SHA-1. Reasons for its downfall are of two key factors, first being that nowadays, computer technology is fast enough to generate 128-bit hash values over and over until hash collision occurs. Second being MD5’s enormous popularity of usage worldwide. Google, for instance, has played a major role in breaking MD5 through distributing hashing generator software over the web. When you type in MD5 in Google’s search bar, the results are endless. The ubiquitous distribution and overuse of it indicates that now almost all English vocabulary, letters and numbers are solved by MD5, allowing anyone to reverse engineer the password. For example, you might have seen Google suggest users to use a ‘strong password’, which looks like a string of random combinations of numbers and letters, but it is actually an English word de facto generated and stored by MD5 in the keychain. It’s noteworthy to mention that as computational technology advances, older versions of hash functions become more vulnerable to attack and are likely to be succeeded with new ones.
Final Thoughts
So, now that we learn about hashing collision, you might wonder if the security of data is just at the mercy of computational technology and advanced mathematical underpinning. Given that computer scientists have devoted years into developing the algorithms, are the broken ones doomed to be thrown out intermittently when new ones come along? The answer to that is tricky. Some consider the collisions are seriously endangering particular sets of security functions, but the concern for deployments of rest of the functionalities remain unknown. Best way to describe the complexity of the situation is that “the alarm is on, but there is no visible fire or smoke. It is time to walk towards the exits — but not to run.”
The important question here is, how can we prevent ourselves from the potential attacks and fraudulent practices? Here are a few solutions to that.
- Choose large bits of the output length of the hash function. When the length is large enough, it will make attacks computationally infeasible. The limit to that, however, is the energy cost and time spent which used to patiently run a through taxing algorithm just in the right speed.
- Practice good security protocols. Double check the documents. It doesn’t hurt to make small modifications if you detect anything suspicious with the document before signing it off.
Resources
hashing algorithms and security – computerphile
Hashing vs Encryption Difference
The Sacred Labor of Love : Scribes and the Ancient Art of Making a Torah Scrool
https://security.googleblog.com/2017/02/announcing-first-sha1-collision.html